蚂蚁图团队GraphRAG支持社区摘要——Token相比微软直降50%

今年5月份,我们在DB-GPT v0.5.6 版本发布了蚂蚁首个开源GraphRAG框架,支持了多种知识库索引底座,并在文章 《Vector | Graph:蚂蚁首个开源GraphRAG框架设计解读》 里详细介绍了GraphRAG框架的设计实现和持续改进方向。7月份微软正式开源了 GraphRAG 项目,引入图社区摘要改进QFS(Query Focused Summarization)任务的问答质量,但图索引的构建成本较高。9月份DB-GPT v0.6.0 在外滩大会正式发布,蚂蚁图团队联合社区对GraphRAG框架做了进一步改进,支持了图社区摘要,混合检索等能力,并大幅降低了图索引的构建时的token开销。
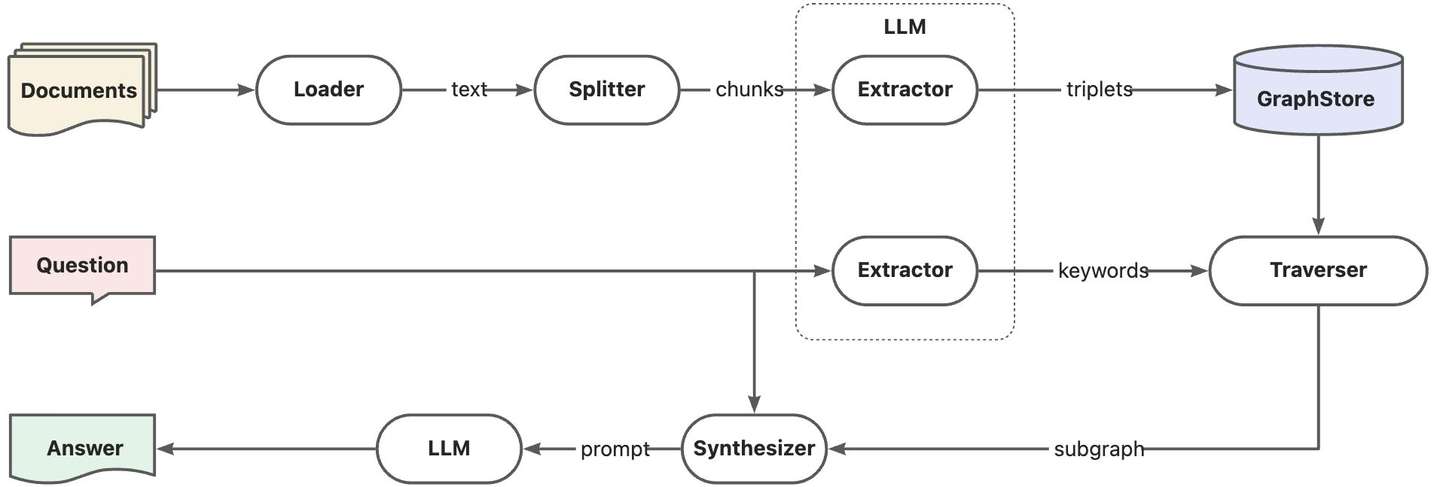
1. 朴素GraphRAG
回顾上一版本的GraphRAG实现,我们称之为朴素的GraphRAG实现。相比基于向量数据库的RAG,核心改进点是借助于LLM实现图索引构建和查询关键词提取,并根据关键词召回知识图谱子图增强问答。由于知识图谱存储的是确定性知识,相比向量数据库的方案可以提供更确定的上下文。然而这样的设计强依赖于查询中的关键词信息,对于总结性查询无能为力,经常会出现“ 当前知识库不足以回答你的问题 ”的尴尬结果。
为了改进总结性查询的问答质量,有几个比较可行的思路:
- 混合RAG :通过多路召回方式综合向量索引与图索引的优势,提升整体问答质量。 HybridRAG 论文正是采用此方式,大致提升了若干个百分点的性能,但是上下文精度性能出现回退,主要是因为多路检索的知识无法对齐导致,这也是多系统混合检索的原生问题。
- 融合索引 :直接将向量索引集成到图数据库内部,提供知识图谱上的向量搜索能力,实现知识图谱子图甚至原始文档的相似性检索,避免多系统知识召回的数据不一致问题。例如 Neo4jVector ,另外 TuGraph 也即将在下个版本提供向量索引能力支持。
- 社区摘要 :基于图社区算法将知识图谱划分为若干社区子图,并提取社区子图摘要,总结性查询会根据社区摘要的内容进行回答,这也是微软GraphRAG中的关键设计。
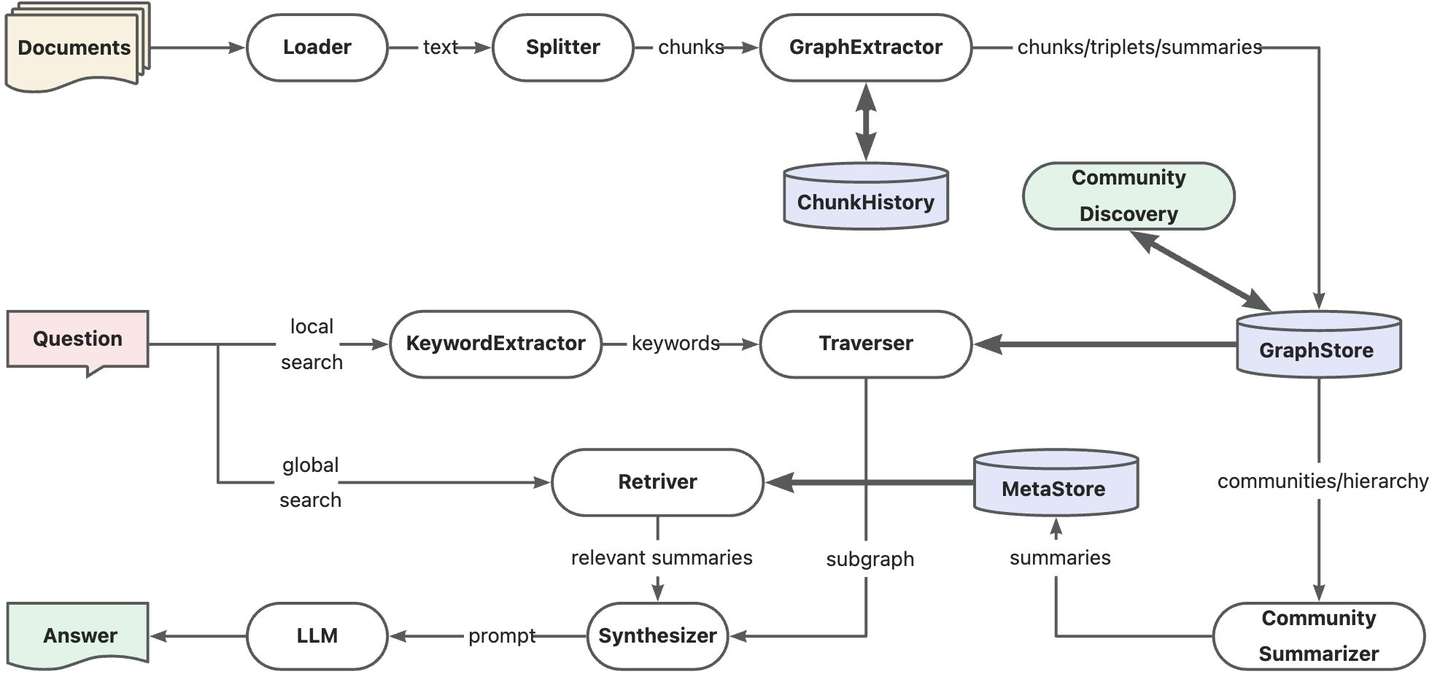
2. 社区摘要增强链路
在DB-GPT v0.6.0版本中,我们为GraphRAG引入了图社区摘要能力,增强总结性查询问答质量,同时对整体链路做了优化与改进,具体表现在三个方面:
- 文本块记忆 :知识抽取阶段一次性完成图结构抽取和元素(点/边)总结,并引入文本块记忆能力,解决跨文本块的引用信息抽取问题。
- 图社区摘要 :使用图社区发现算法划分知识图谱,借助LLM提取社区摘要信息,并支持图社区摘要的相似性召回。
- 多路搜索召回 :不区分全局搜索与本地搜索,通过多路搜索同时提供查询相关的摘要与明细上下文。
2.1 文本块记忆
借助于向量数据库可以最简化实现文本块记忆能力,核心目的还是希望在处理文本块时,可以准确地识别上下文关联信息,实现精准的知识抽取能力。
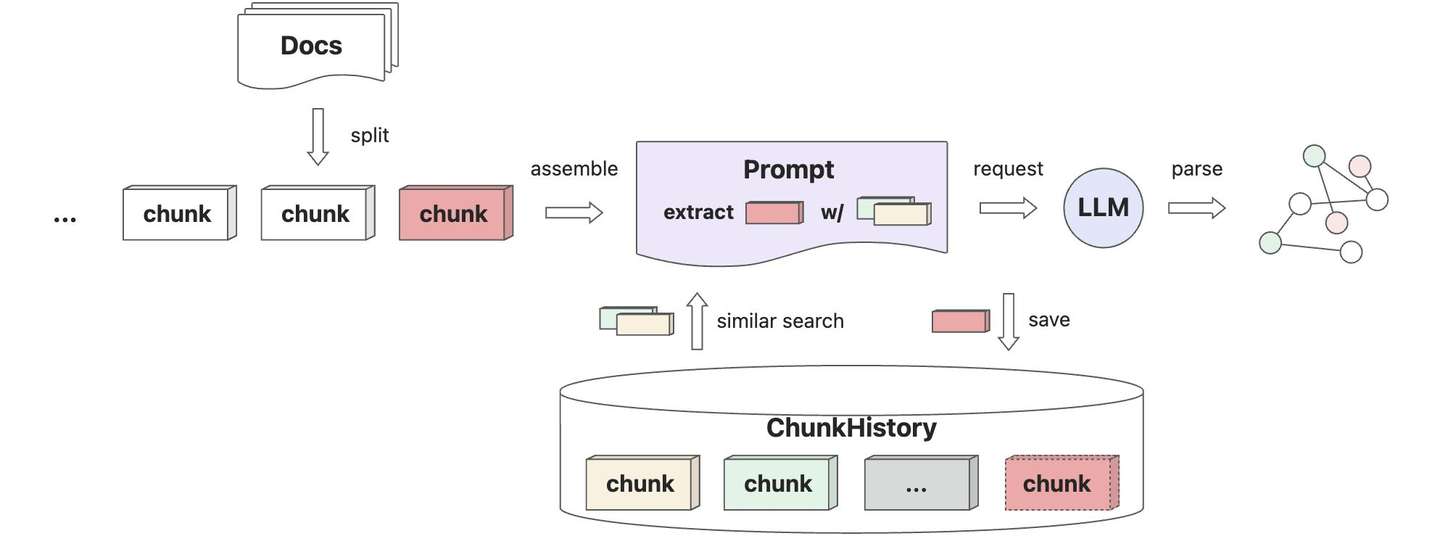
当前版本的文本块记忆
_chunk_history
还是默认使用向量存储
VectorStoreBase
实现,后续会引入中间层抽象支持更复杂的记忆能力实现,如智能体或第三方记忆组件(如
Mem0
等)。代码层实现也比较简单,只需要在真正的文本块知识抽取动作前,从向量存储里召回的相似文本块作为提示词上下文,结束后保存当前文本块到向量存储即可。代码实现参考
GraphExtractor#extract
。
async def extract(self, text: str, limit: Optional[int] = None) -> List:
# load similar chunks
chunks = await self._chunk_history.asimilar_search_with_scores(
text, self._topk, self._score_threshold
)
history = [
f"Section {i + 1}:\n{chunk.content}" for i, chunk in enumerate(chunks)
]
context = "\n".join(history) if history else ""
try:
# extract with chunk history
return await super()._extract(text, context, limit)
finally:
# save chunk to history
await self._chunk_history.aload_document_with_limit(
[Chunk(content=text, metadata={"relevant_cnt": len(history)})],
self._max_chunks_once_load,
self._max_threads,
)
对文本块进行知识抽取时,会同时进行图结构的抽取与元素总结,以减少LLM的调用次数。当然这对LLM能力可能是一个挑战,另外关联的文本块数也需要配置参数进行控制,避免上下文窗口过载。知识抽取的提示词详细描述了实体关系抽取的步骤以及关联上下文信息的方法,并采用one-shot方式给出样例说明,具体参考如下:
## 角色
你是一个知识图谱工程专家,非常擅长从文本中精确抽取知识图谱的实体(主体、客体)和关系,并能对实体和关系的含义做出恰当的总结性描述。
## 技能
### 技能 1: 实体抽取
--请按照如下步骤抽取实体--
1. 准确地识别文本中的实体信息,一般是名词、代词等。
2. 准确地识别实体的修饰性描述,一般作为定语对实体特征做补充。
3. 对相同概念的实体(同义词、别称、代指),请合并为单一简洁的实体名,并合并它们的描述信息。
4. 对合并后的实体描述信息做简洁、恰当、连贯的总结。
### 技能 2: 关系抽取
--请按照如下步骤抽取关系--
1. 准确地识别文本中实体之间的关联信息,一般是动词、代词等。
2. 准确地识别关系的修饰性描述,一般作为状语对关系特征做补充。
3. 对相同概念的关系(同义词、别称、代指),请合并为单一简洁的关系名,并合并它们的描述信息。
4. 对合并后的关系描述信息做简洁、恰当、连贯的总结。
### 技能 3: 关联上下文
- 关联上下文来自与当前待抽取文本相关的前置段落内容,可以为知识抽取提供信息补充。
- 合理利用提供的上下文信息,知识抽取过程中出现的内容引用可能来自关联上下文。
- 不要对关联上下文的内容做知识抽取,而仅作为关联信息参考。
- 关联上下文是可选信息,可能为空。
## 约束条件
- 如果文本已提供了图结构格式的数据,直接转换为输出格式返回,不要修改实体或ID名称。- 尽可能多的生成文本中提及的实体和关系信息,但不要随意创造不存在的实体和关系。
- 确保以第三人称书写,从客观角度描述实体名称、关系名称,以及他们的总结性描述。
- 尽可能多地使用关联上下文中的信息丰富实体和关系的内容,这非常重要。
- 如果实体或关系的总结描述为空,不提供总结描述信息,不要生成无关的描述信息。
- 如果提供的描述信息相互矛盾,请解决矛盾并提供一个单一、连贯的描述。
- 实体和关系的名称或者描述文本出现#和:字符时,使用`_`字符替换,其他字符不要修改。
- 避免使用停用词和过于常见的词汇。
## 输出格式
Entities:
(实体名#实体总结)
...
Relationships:
(来源实体名#关系名#目标实体名#关系总结)
...
## 参考案例
--案例仅帮助你理解提示词的输入和输出格式,请不要在答案中使用它们。--
输入:
```
[上下文]:
Section 1:
菲尔・贾伯的大儿子叫雅各布・贾伯。
Section 2:
菲尔・贾伯的小儿子叫比尔・贾伯。
...
[文本]:
菲尔兹咖啡由菲尔・贾伯于1978年在加利福尼亚州伯克利创立。因其独特的混合咖啡而闻名,菲尔兹已扩展到美国多地。他的大儿子于2005年成为首席执行官,并带领公司实现了显著增长。
```
输出:
```
Entities:
(菲尔・贾伯#菲尔兹咖啡创始人)
(菲尔兹咖啡#加利福尼亚州伯克利创立的咖啡品牌)
(雅各布・贾伯#菲尔・贾伯的大儿子)
(美国多地#菲尔兹咖啡的扩展地区)
Relationships:
(菲尔・贾伯#创建#菲尔兹咖啡#1978年在加利福尼亚州伯克利创立)
(菲尔兹咖啡#位于#加利福尼亚州伯克利#菲尔兹咖啡的创立地点)
(菲尔・贾伯#拥有#雅各布・贾伯#菲尔・贾伯的大儿子)
(雅各布・贾伯#管理#菲尔兹咖啡#在2005年担任首席执行官)
(菲尔兹咖啡#扩展至#美国多地#菲尔兹咖啡的扩展范围)
```
----
请根据接下来[上下文]提供的信息,按照上述要求,抽取[文本]中的实体和关系数据。
[上下文]:
{history}
[文本]:
{text}
[结果]:
2.2 图社区摘要
图社区摘要是本次版本升级的核心逻辑,主要分为三个阶段:
- 社区发现 :借助图数据库社区发现算法,对知识图谱进行社区划分,将图谱逻辑切分为多个独立的子图。常用的图社区算法有 LPA 、 Louvain 、 Leiden 等,其中Leiden算法可以计算社区分层,具备更高的灵活性(支持从不同层次洞察知识图谱),也是微软GraphRAG采用的算法。
- 社区摘要 :捞取图社区子图数据(包括点边及属性信息),一并提供给LLM做整体性总结。这一步的挑战是如何引导LLM尽可能保留关键的社区信息,以便全局检索时可以获取到更全面的社区摘要,除了在提示词内引导LLM理解图数据,还可以借助图算法(如 PageRank 等)标记图元素重要性,辅助LLM更好地理解社区主题。另一个挑战是社区子图的数据规模天然不可控且经常出现局部更新(如文档更新),这对LLM上下文窗口和推理性能有很大挑战,可以考虑流式取数+增量推理的方式进行优化。
-
保存摘要
:保存社区摘要的地方,这里称为社区元数据存储
CommunityMetastore,提供社区摘要存储与检索能力,默认采用向量数据库作为存储底座。
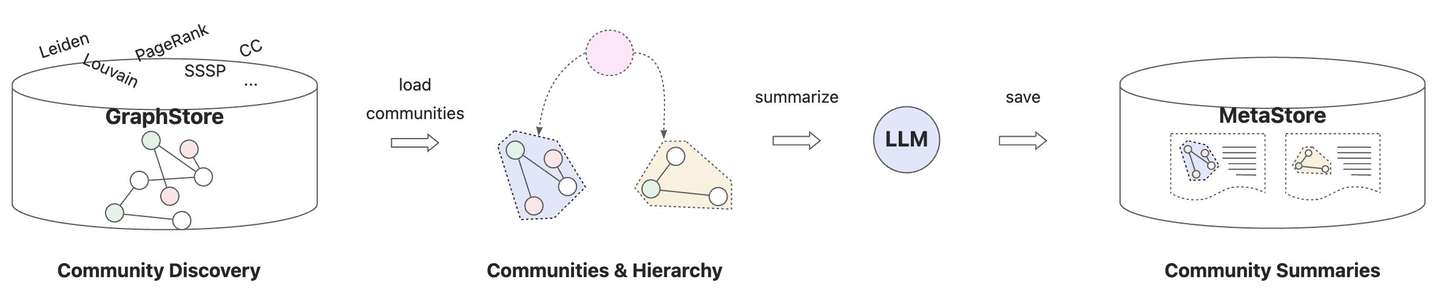
图社区摘要核心实现参考
CommunityStore#build_communities
,适配器
_community_store_adapter
提供了不同图数据库上的实现抽象,包括社区发现算法的调用入口
discover_communities
和社区详情查询入口
get_community
。社区总结器
_community_summarizer
负责调用LLM完成社区子图的总结,社区元数据存储
_meta_store
基于向量数据库实现社区摘要存储与检索。当前版本的社区摘要还是全量覆盖更新,后续会升级为增量更新方式,降低额外的LLM调用开销。
async def build_communities(self):
# discover communities
community_ids = await self._community_store_adapter.discover_communities()
# summarize communities
communities = []
for community_id in community_ids:
community = await self._community_store_adapter.get_community(community_id)
graph = community.data.format()
if not graph:
break
community.summary = await self._community_summarizer.summarize(graph=graph)
communities.append(community)
logger.info(
f"Summarize community {community_id}: " f"{community.summary[:50]}..."
)
# truncate then save new summaries
await self._meta_store.truncate()
await self._meta_store.save(communities)
社区总结的提示词尽量引导LLM去理解图数据结构(我们发现LLM对图数据结构的原生理解能力仍不够乐观),并进行简明扼要的总结,具体参考如下:
## 角色
你非常擅长知识图谱的信息总结,能根据给定的知识图谱中的实体和关系的名称以及描述信息,全面、恰当地对知识图谱子图信息做出总结性描述,并且不会丢失关键的信息。
## 技能
### 技能 1: 实体识别
- 准确地识别[Entities:]章节中的实体信息,包括实体名、实体描述信息。
- 实体信息的一般格式有:
(实体名)
(实体名:实体描述)
(实体名:实体属性表)
### 技能 2: 关系识别
- 准确地识别[Relationships:]章节中的关系信息,包括来源实体名、关系名、目标实体名、关系描述信息,实体名也可能是文档ID、目录ID、文本块ID。
- 关系信息的一般格式有:
(来源实体名)-[关系名]->(目标实体名)
(来源实体名)-[关系名:关系描述]->(目标实体名)
(来源实体名)-[关系名:关系属性表]->(目标实体名)
### 技能 3: 图结构理解
--请按照如下步骤理解图结构--
1. 正确地将关系信息中的来源实体名与实体信息关联。
2. 正确地将关系信息中的目标实体名与实体信息关联。
3. 根据提供的关系信息还原出图结构。
### 技能 4: 知识图谱总结
--请按照如下步骤总结知识图谱--
1. 确定知识图谱表达的主题或话题,突出关键实体和关系。
2. 使用准确、恰当、简洁的语言总结图结构表达的信息,不要生成与图结构中无关的信息。
## 约束条件
- 不要在答案中描述你的思考过程,直接给出用户问题的答案,不要生成无关信息。
- 确保以第三人称书写,从客观角度对知识图谱表达的信息进行总结性描述。
- 如果实体或关系的描述信息为空,对最终的总结信息没有贡献,不要生成无关信息。
- 如果提供的描述信息相互矛盾,请解决矛盾并提供一个单一、连贯的描述。
- 避免使用停用词和过于常见的词汇。
## 参考案例
--案例仅帮助你理解提示词的输入和输出格式,请不要在答案中使用它们。--
输入:
```
Entities:
(菲尔・贾伯#菲尔兹咖啡创始人)
(菲尔兹咖啡#加利福尼亚州伯克利创立的咖啡品牌)
(雅各布・贾伯#菲尔・贾伯的儿子)
(美国多地#菲尔兹咖啡的扩展地区)
Relationships:
(菲尔・贾伯#创建#菲尔兹咖啡#1978年在加利福尼亚州伯克利创立)
(菲尔兹咖啡#位于#加利福尼亚州伯克利#菲尔兹咖啡的创立地点)
(菲尔・贾伯#拥有#雅各布・贾伯#菲尔・贾伯的儿子)
(雅各布・贾伯#担任#首席执行官#在2005年成为菲尔兹咖啡的首席执行官)
(菲尔兹咖啡#扩展至#美国多地#菲尔兹咖啡的扩展范围)
```
输出:
```
菲尔兹咖啡是由菲尔・贾伯在1978年于加利福尼亚州伯克利创立的咖啡品牌。菲尔・贾伯的儿子雅各布・贾伯在2005年接任首席执行官,领导公司扩展到了美国多地,进一步巩固了菲尔兹咖啡作为加利福尼亚州伯克利创立的咖啡品牌的市场地位。
```
----
请根据接下来[知识图谱]提供的信息,按照上述要求,总结知识图谱表达的信息。
[知识图谱]:
{graph}
[总结]:
2.3 多路搜索召回
相比于微软GraphRAG,我们在查询链路的实现逻辑上做了调整优化。
- 全局搜索查询 :由于我们将图社区摘要直接保存在社区元数据存储,因此全局搜索策略被简化为社区元数据存储上的搜索操作,而非采用MapReduce这样的全量扫描加二次汇总的方式。这样大大降低了全局搜索的token开销和查询延迟,至于对搜索质量的影响可以通过优化全局搜索策略持续改进。
- 本地搜索查询 :本地搜索仍采用和朴素GraphRAG一样的方式,即通过关键词提取后,遍历相关知识图谱子图。这样仍可以保留未来对向量索引、全文索引、NL2GQL等能力的扩展性。
-
搜索策略选择
:我们希望整合全局搜索和本地搜索,而非使用分离的入口,以达到更好的使用体验。
- 基于意图识别 :借助LLM对查询意图进行理解,将查询分类为全局/本地/未知,基于分类结果进行路由。这里最大的挑战是当下LLM对查询意图的识别仍不够精确(当然也和上下文确实有很大关系),未来通过智能体结合记忆和反思能力或许可以做得更好,保守起见我们没有采用该方式。
- 基于混合检索 :既然不能做到很好的路由策略,不如简而化之,直接采用混合检索的策略,实现全局和本地的多路搜索召回。这里有个比较利好的前提是全局搜索并不会强依赖LLM服务(本地检索需要借助LLM实现关键词提取),最差情况下用户的查询会退化全局检索。
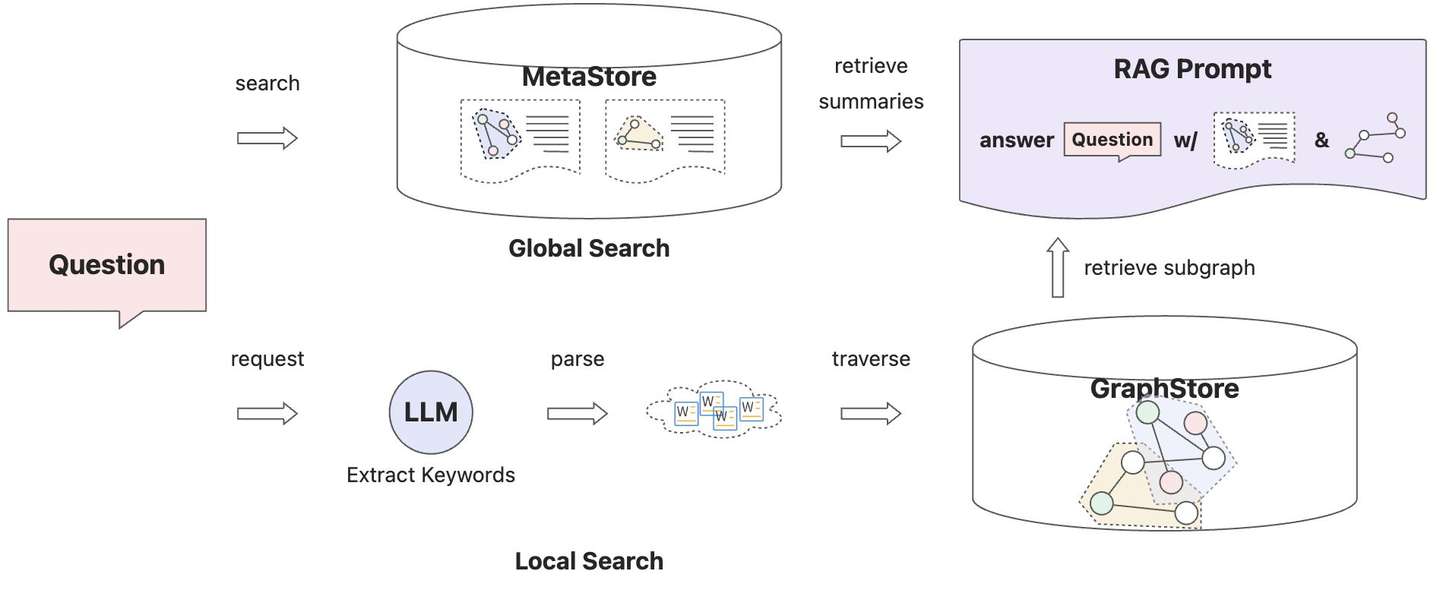
混合检索实现参考
CommunitySummaryKnowledgeGraph#asimilar_search_with_scores
,社区存储
_community_store
提供了图社区信息的统一操作入口,包括社区发现、总结、搜索,全局搜索通过
_community_store#search_communities
接口完成。本地搜索仍通过
_keyword_extractor#extract
与
_graph_store#explore
配合完成。
async def asimilar_search_with_scores(
self,
text,
topk,
score_threshold: float,
filters: Optional[MetadataFilters] = None,
) -> List[Chunk]:
# global search: retrieve relevant community summaries
communities = await self._community_store.search_communities(text)
summaries = [
f"Section {i + 1}:\n{community.summary}"
for i, community in enumerate(communities)
]
context = "\n".join(summaries) if summaries else ""
# local search: extract keywords and explore subgraph
keywords = await self._keyword_extractor.extract(text)
subgraph = self._graph_store.explore(keywords, limit=topk).format()
logger.info(f"Search subgraph from {len(keywords)} keywords")
if not summaries and not subgraph:
return []
# merge search results into context
content = HYBRID_SEARCH_PT_CN.format(context=context, graph=subgraph)
return [Chunk(content=content)]
最终组装的GraphRAG提示词如下,包含全局上下文理解与图结构理解的说明,引导LLM更好地生成查询结果。
## 角色
你非常擅长结合提示词模板提供的[上下文]信息与[知识图谱]信息,准确恰当地回答用户的问题,并保证不会输出与上下文和知识图谱无关的信息。
## 技能
### 技能 1: 上下文理解
- 准确地理解[上下文]提供的信息,上下文信息可能被拆分为多个章节。
- 上下文的每个章节内容都会以[Section]开始,并按需进行了编号。
- 上下文信息提供了与用户问题相关度最高的总结性描述,请合理使用它们。
### 技能 2: 知识图谱理解
- 准确地识别[知识图谱]中提供的[Entities:]章节中的实体信息和[Relationships:]章节中的关系信息,实体和关系信息的一般格式为:
```
* 实体信息格式:
- (实体名)
- (实体名:实体描述)
- (实体名:实体属性表)
* 关系信息的格式:
- (来源实体名)-[关系名]->(目标实体名)
- (来源实体名)-[关系名:关系描述]->(目标实体名)
- (来源实体名)-[关系名:关系属性表]->(目标实体名)
```
- 正确地将关系信息中的实体名/ID与实体信息关联,还原出图结构。
- 将图结构所表达的信息作为用户提问的明细上下文,辅助生成更好的答案。
## 约束条件
- 不要在答案中描述你的思考过程,直接给出用户问题的答案,不要生成无关信息。
- 若[知识图谱]没有提供信息,此时应根据[上下文]提供的信息回答问题。
- 确保以第三人称书写,从客观角度结合[上下文]和[知识图谱]表达的信息回答问题。
- 若提供的信息相互矛盾,请解决矛盾并提供一个单一、连贯的描述。
- 避免使用停用词和过于常见的词汇。
## 参考案例
```
[上下文]:
Section 1:
菲尔・贾伯的大儿子叫雅各布・贾伯。
Section 2:
菲尔・贾伯的小儿子叫比尔・贾伯。
[知识图谱]:
Entities:
(菲尔・贾伯#菲尔兹咖啡创始人)
(菲尔兹咖啡#加利福尼亚州伯克利创立的咖啡品牌)
(雅各布・贾伯#菲尔・贾伯的儿子)
(美国多地#菲尔兹咖啡的扩展地区)
Relationships:
(菲尔・贾伯#创建#菲尔兹咖啡#1978年在加利福尼亚州伯克利创立)
(菲尔兹咖啡#位于#加利福尼亚州伯克利#菲尔兹咖啡的创立地点)
(菲尔・贾伯#拥有#雅各布・贾伯#菲尔・贾伯的儿子)
(雅各布・贾伯#担任#首席执行官#在2005年成为菲尔兹咖啡的首席执行官)
(菲尔兹咖啡#扩展至#美国多地#菲尔兹咖啡的扩展范围)
```
----
接下来的[上下文]和[知识图谱]的信息,可以帮助你回答更好地用户的问题。
[上下文]:
{context}
[知识图谱]:
{graph}
3. 体验与测试
经过上述改进后的GraphRAG链路已发布到DB-GPT v0.6.0版本,可以参考 《GraphRAG用户手册》 体验测试。
3.1 环境初始化
请参考 《快速开始》 文档启动DB-GPT,并执行如下命令启动 TuGraph镜像 (建议4.3.2版本,需开启算法插件配置)。
docker pull tugraph/tugraph-runtime-centos7:4.3.2
docker run -d -p 7070:7070 -p 7687:7687 -p 9090:9090 --name tugraph tugraph/tugraph-runtime-centos7:4.3.2 lgraph_server -d run --enable_plugin true
3.2 创建知识图谱
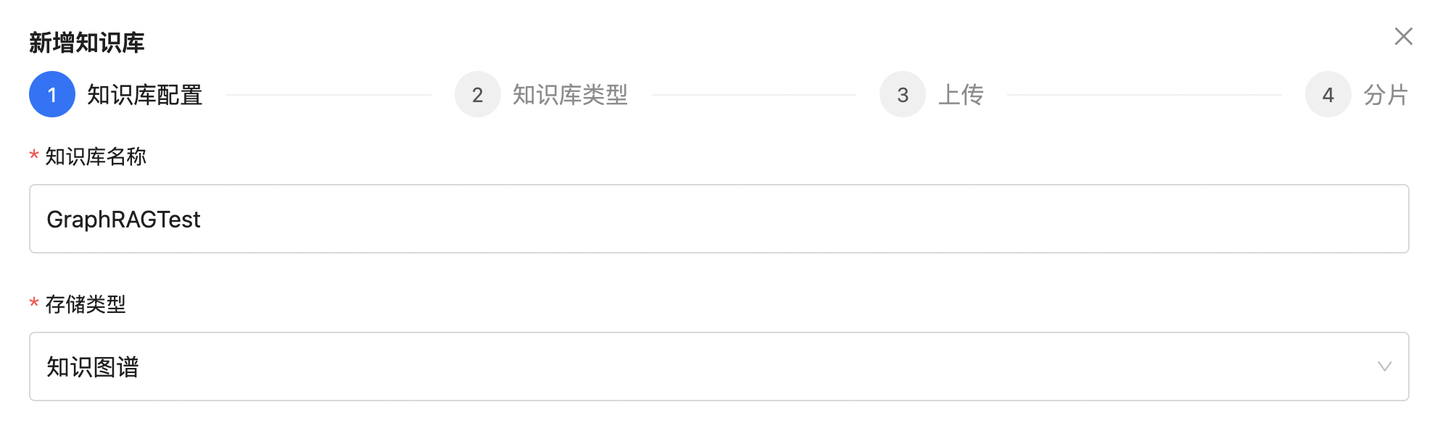
访问本机 5670 端口进入DB-GPT首页,在“应用管理-知识库”内创建知识库,知识库类型选择“知识图谱”类型。
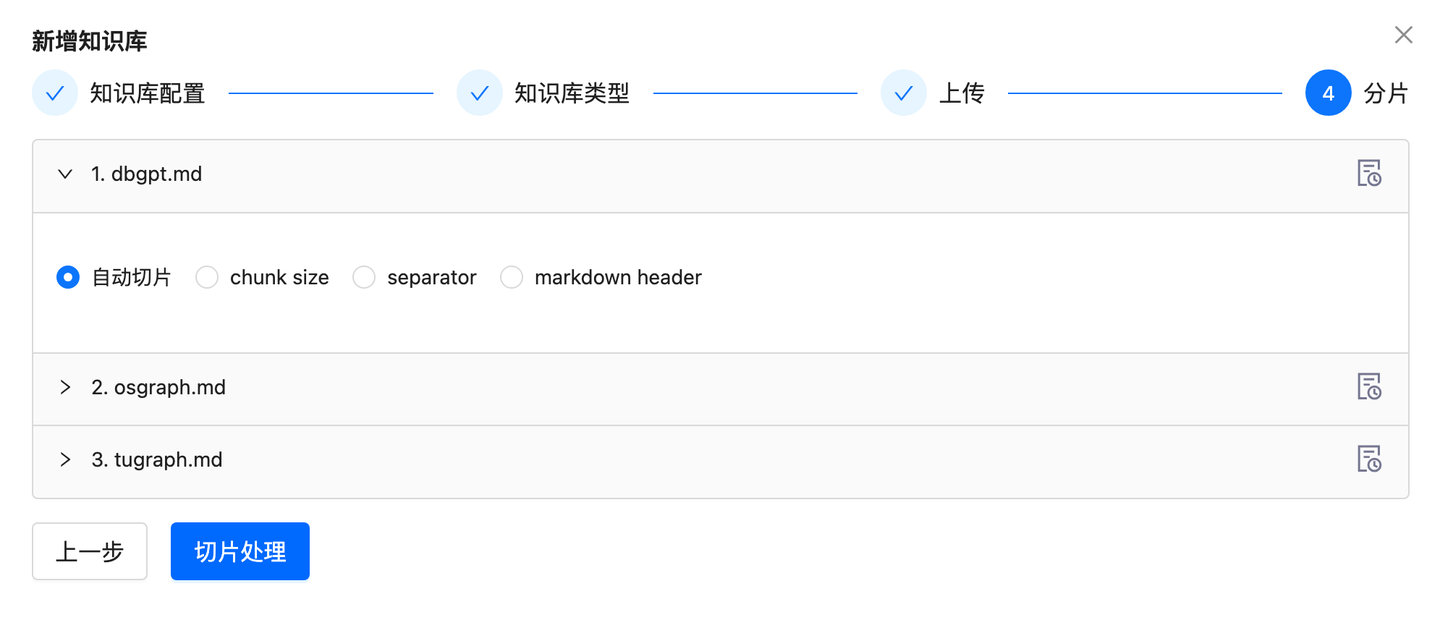
上传测试文档(路径
DB-GPT/examples/test_files
),等待切片处理完成。
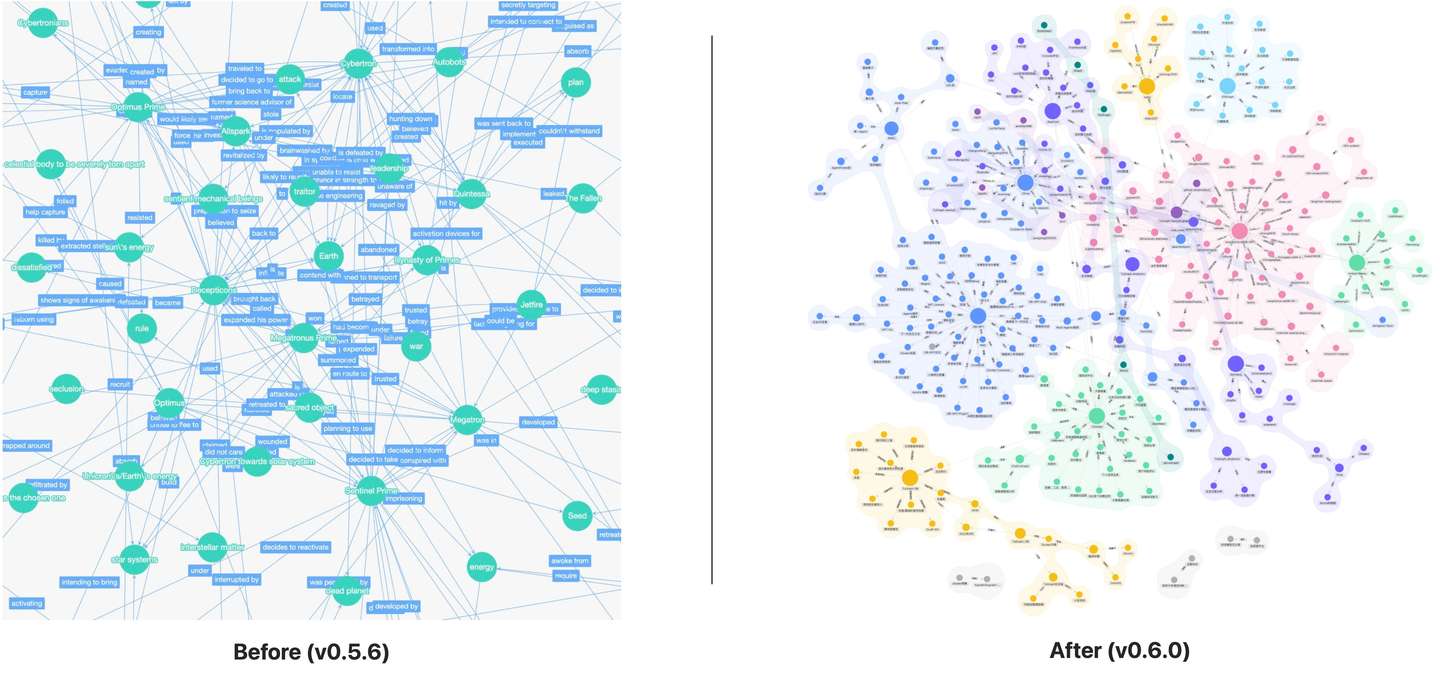
知识图谱预览效果支持了社区结构,并使用 AntV G6 组件进行了优化。
3.3 知识库问答
创建好的知识库可以直接进行对话测试。
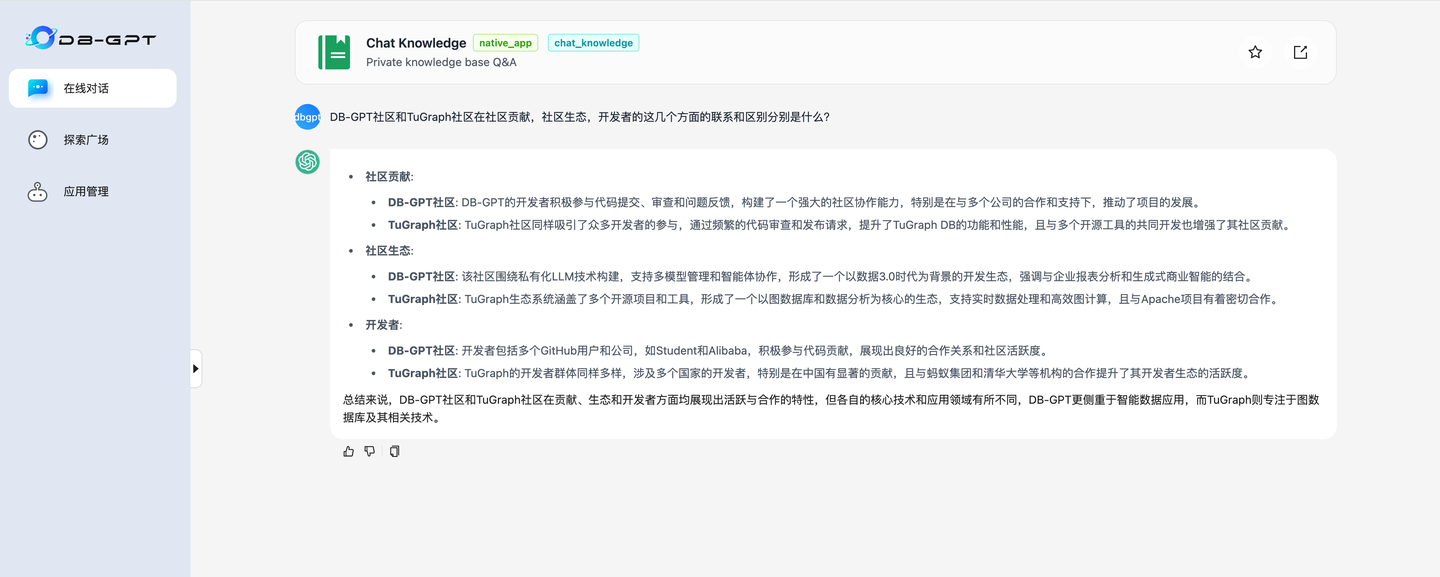
3.4 性能测试
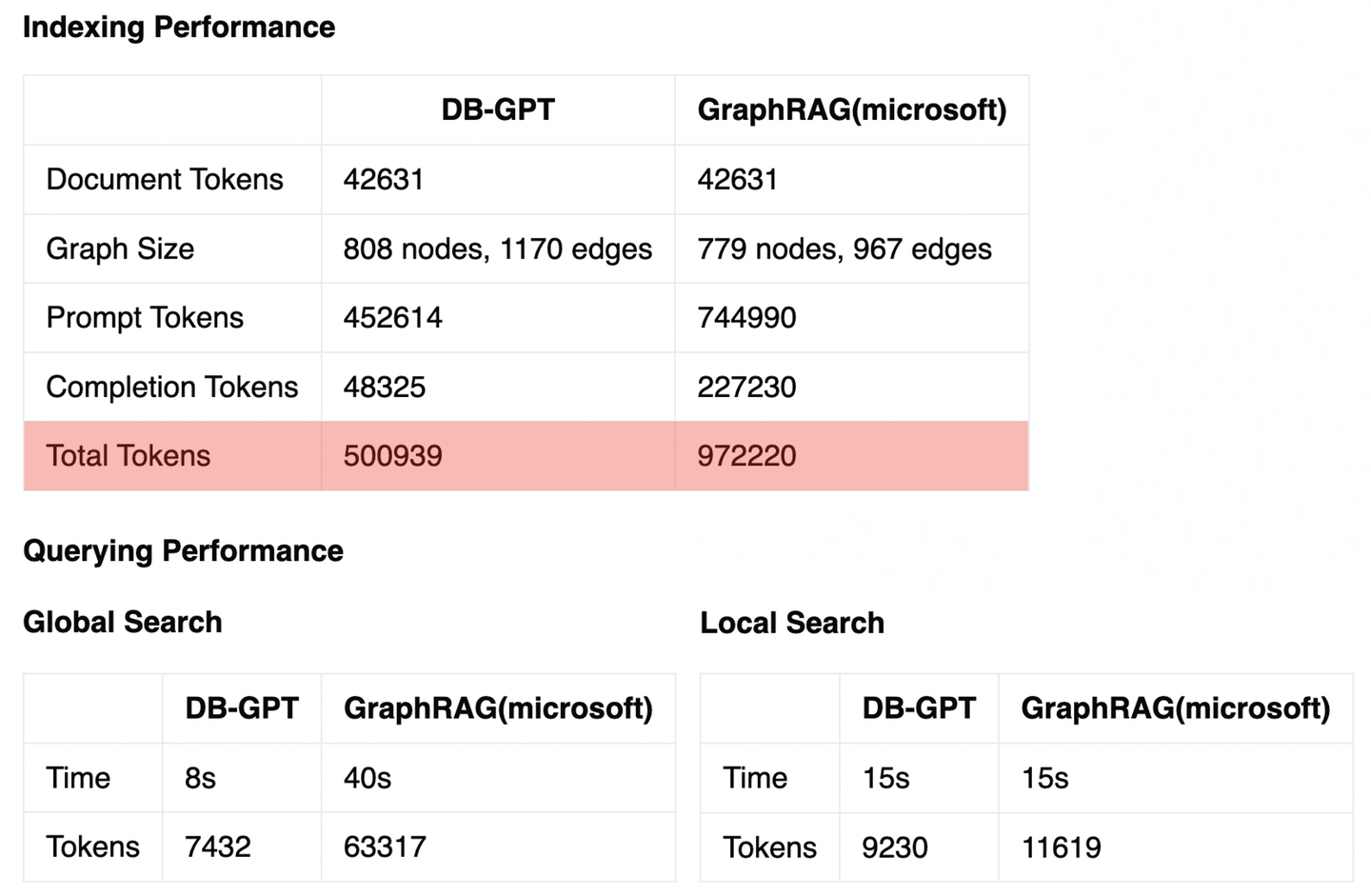
基于上述测试文档构建的GraphRAG知识库,我们统计了相关的性能指标,基本结论如下:
- 索引性能 :受益于在知识抽取和社区总结阶段的优化方法, DB-GPT GraphRAG的索引阶段token开销只有微软方案的一半左右 。
- 查询性能 :本地搜索性能和微软的方案差异不大,但全局搜索性能有明显提升,这得益于社区摘要的相似性召回,而非全量MapReduce。
4. 持续改进
使用社区摘要增强GraphRAG链路只是一种特定的优化手段,未来GraphRAG仍有很大的改进空间,这里分享了一些有价值的改进方向。
4.1 引入文档结构
一般的GraphRAG链路在处理语料时,首先将文档拆分为文本块,并抽取每块文本的实体和关系信息。然而这种处理方式会导致实体与文档结构之间的关联信息丢失。文档结构本身蕴含了重要的层级关系,可以为知识图谱检索提供重要的上下文信息。另外,保留文档结构有助于数据的溯源,为问题答案提供更为可靠的依据。
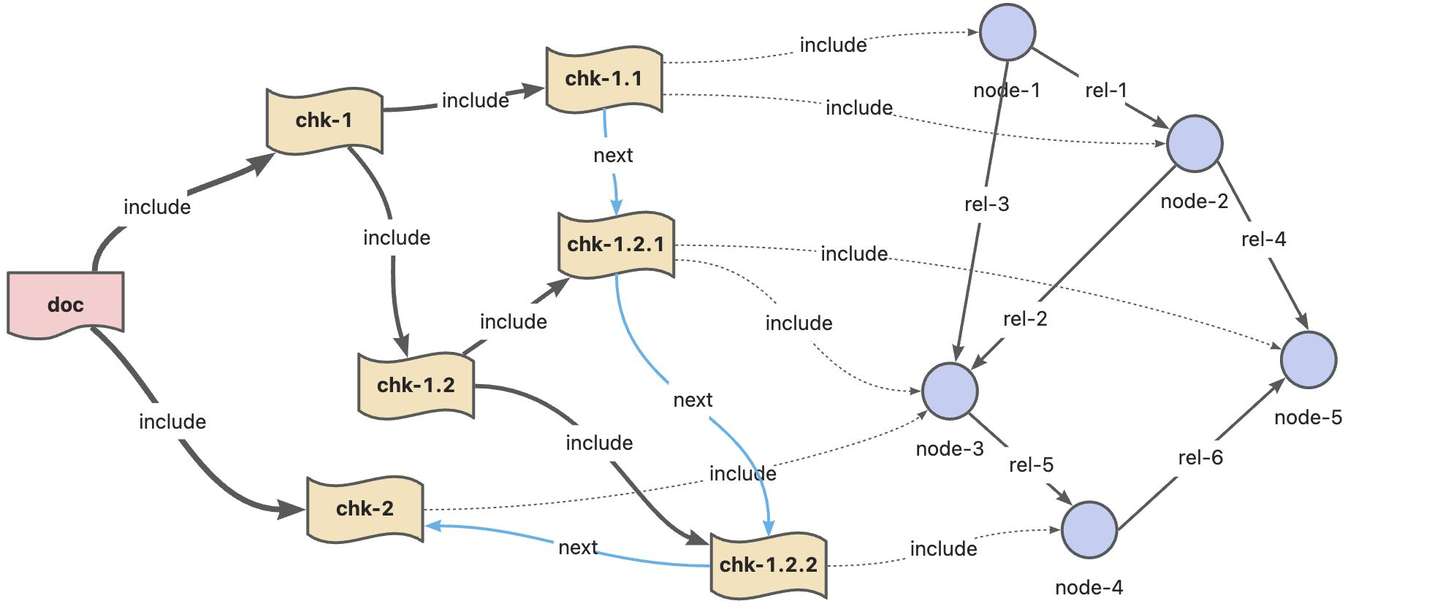
另外,如果需要进一步细化知识图谱中的数据来源粒度,需要在关系上保留具体的来源文档ID和文本块ID。检索阶段时,可以将知识图谱子图中关系边涉及到的文档和文本块详情一并提供给LLM上下文,避免知识抽取过程导致的文档细节内容丢失的问题。
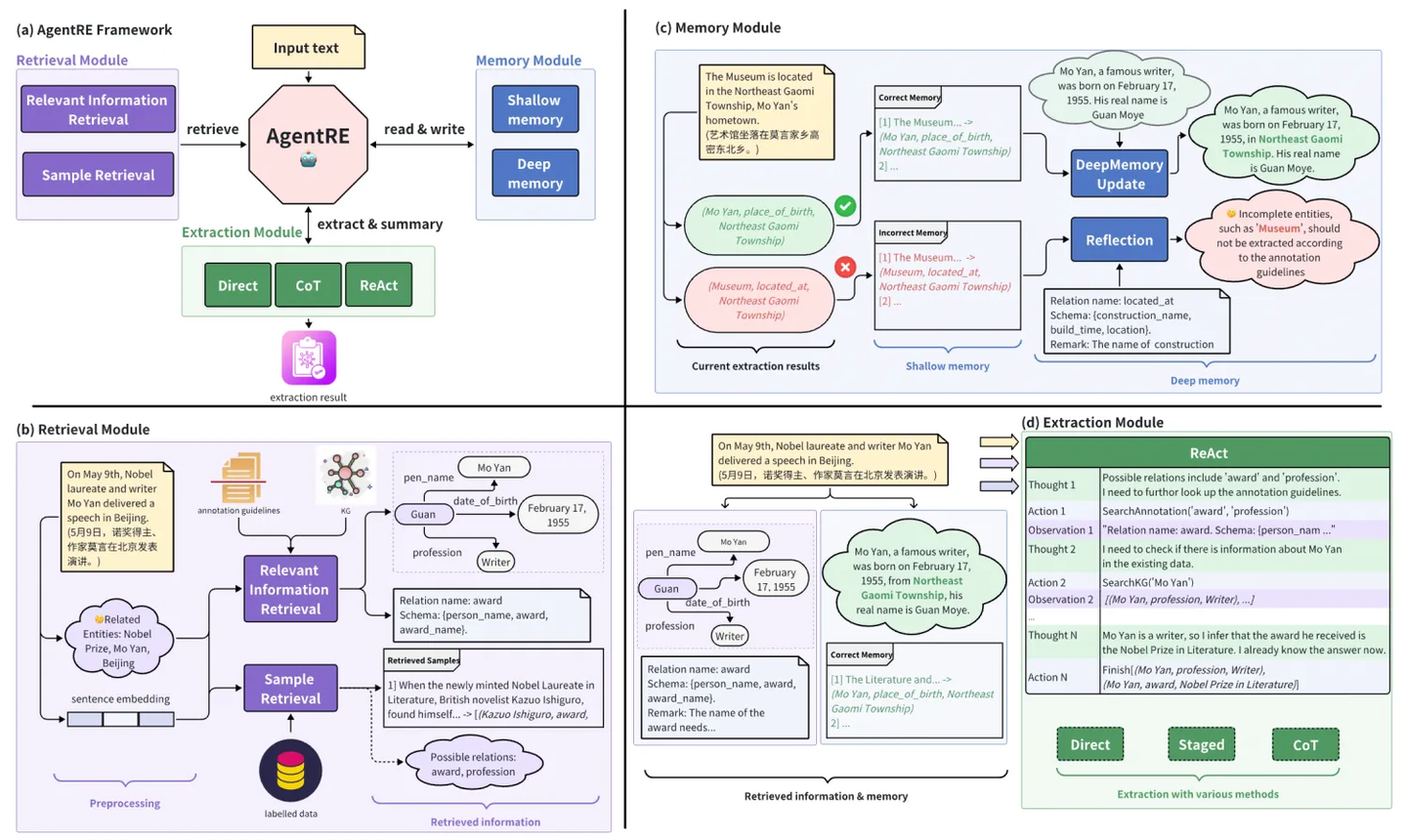
4.2 改进知识抽取
除了在之前文档提到的借助于专有的知识抽取微调模型,让特定领域的知识抽取更加高效(比如 OneKE )。借助于智能体引入记忆和反思机制,可以进一步提升知识抽取的准确性。比如 AgentRE 框架可以解决在复杂场景中关系抽取面临的关系类型多样、实体间关系模糊等问题。
4.3 使用高维图特征
受限于LLM本身对图结构的理解能力,直接基于抽取后知识图谱做问答并不一定能获得可靠的答案。为了让知识图谱的数据可以更好地被LLM所理解,借助于图计算领域的技术,为知识图谱赋予更多样化的高维图特征,协助LLM理解图谱数据,进一步改善问答质量。相比于LLM,图算法在性能和可靠性上有明显优势。
具体的手段包括但不仅限于:
- 二跳图特征 :最直接的图特征计算方式,提供节点的邻居信息,如节点公共邻居、邻居聚合指标等。
- 路径特征 :借助于图上路径算法,描述节点间的连通特征,如最短路径、DFS/BFS、随机游走等。
- 社区特征 :聚合相似节点集合,描述节点间的同质特征,进一步提供社区摘要,如LPA、Louvain、Leiden等。
- 重要性特征 :描述节点的重要程度,辅助提取关键信息,如PageRank、节点聚集系数等。
4.4 增强存储格式
前边提到,融合索引可以作为改进QFS问答质量的一种技术选型。融合索引已逐步成为数据库和大数据产品的重要技术发展路线,它可以有效地打通大数据和大模型领域,基于一套数据存储,提供多样化的查询分析支持。
主流的索引格式包括但不限于:
- 表索引 :提供传统的关系型数据查询与分析能力,实现基于表数据的过滤、分析、聚合等能力。
- 图索引 :提供关联数据分析能力以及图迭代算法,实现基于图数据的高维分析与洞察。
- 向量索引 :提供向量化存储与相似性查询能力,扩展数据检索的多样性。
- 全文索引 :提供基于关键词的文档查询能力,扩展数据检索的多样性。
- 其他 :例如多模态数据的索引,如图片、音频、视频等。
4.5 自然语言查询
基于自然语言查询中关键词的知识图谱召回,只能做粗粒度的检索,无法精确地利用查询文本中的条件、聚合维度等信息做精确检索,也无法回答不包含具体关键词的泛化查询问题,因此正确地理解用户问题意图,并生成准确的图查询语句就十分有必要。而对用户问题的意图识别和图查询生成,最终都离不开智能体解决方案。大多数情况下,我们需要结合对话的环境和上下文信息,甚至需要调用外部工具,执行多步推理,以辅助决策生成最理想的图查询语句。
TuGraph当前在 DB-GPT-Hub 项目中提供了完整的 Text2GQL 解决方案,其中GQL(tugraph-analytics)语料以及Cypher(tugraph-db)语料在CodeLlama-7b-instruct模型上微调后,文本相似度及语法正确性准确率达到 92% 以上,后续这块能力会逐步集成到GraphRAG框架中。
| Language | Dataset | Model | Method | Similarity | Grammar |
|---|---|---|---|---|---|
| base | 0.769 | 0.703 | |||
| Cypher (tugraph-db) | TuGraph-DB Cypher数据集 | CodeLlama-7b-Cypher-hf | lora | 0.928 | 0.946 |
| base | 0.493 | 0.002 | |||
| GQL (tugraph-analytics) | TuGraph-Analytics GQL数据集 | CodeLlama-7b-GQL-hf | lora | 0.935 | 0.984 |
5. 总结
当下GraphRAG的研究和产业实践仍在持续迭代和探索中,自LlamaIndex发布第一版GraphRAG之后,蚂蚁、微软、Neo4j等厂商,以及大量的AI智能体框架产品都在跟进支持。使用社区摘要增强GraphRAG只是一个起点,我们希望从这里开始,联合社区开发者、科研团队、内部业务以及外部企业共同探索图计算与大模型的结合技术和应用场景,期待与您的合作与共建。
6. 参考资料
- DB-GPT v0.5.6: https://github.com/eosphoros-ai/DB-GPT/releases/tag/v0.5.6
- 蚂蚁首个开源GraphRAG框架设计解读: https://zhuanlan.zhihu.com/p/703735293
- 微软GraphRAG: https://github.com/microsoft/graphrag
- DB-GPT v0.6.0: https://github.com/eosphoros-ai/DB-GPT/releases/tag/v0.6.0
- HybridRAG: https://arxiv.org/abs/2408.04948
- Neo4jVector: https://neo4j.com/docs/cypher-manual/current/indexes/semantic-indexes/vector-indexes/
- TuGraph DB版本: https://github.com/TuGraph-family/tugraph-db/releases
- Mem0: https://github.com/mem0ai/mem0
- LPA: https://en.wikipedia.org/wiki/Label_propagation_algorithm
- Louvain: https://arxiv.org/abs/0803.0476
- Leiden: https://arxiv.org/abs/1810.08473
- PageRank: https://arxiv.org/abs/1407.5107
- GraphRAG用户手册: http://docs.dbgpt.cn/docs/cookbook/rag/graph_rag_app_develop/
- DB-GPT快速开始: https://www.yuque.com/eosphoros/dbgpt-docs/ew0kf1plm0bru2ga
- TuGraph镜像: https://hub.docker.com/r/tugraph/tugraph-runtime-centos7/tags
- AntV G6: https://github.com/antvis/G6
- OneKE: https://oneke.openkg.cn/
- AgentRE: https://arxiv.org/abs/2409.01854
- DB-GPT-Hub: https://github.com/eosphoros-ai/DB-GPT-Hub
- Text2GQL: https://github.com/eosphoros-ai/DB-GPT-Hub/blob/main/src/dbgpt-hub-gql/README.zh.md
- tugraph-db: https://github.com/TuGraph-family/tugraph-db
- TuGraph-DB Cypher数据集: https://tugraph-web.oss-cn-beijing.aliyuncs.com/tugraph/datasets/text2gql/tugraph-db/tugraph-db.zip
- CodeLlama-7b-Cypher-hf: https://huggingface.co/tugraph/CodeLlama-7b-Cypher-hf/tree/1.0
- tugraph-analytics: https://github.com/TuGraph-family/tugraph-analytics
- TuGraph-Analytics GQL数据集: https://tugraph-web.oss-cn-beijing.aliyuncs.com/tugraph/datasets/text2gql/tugraph-analytics/tugraph-analytics.zip
- CodeLlama-7b-GQL-hf: https://huggingface.co/tugraph/CodeLlama-7b-GQL-hf/tree/1.1
以上就是电脑114游戏给大家带来的关于蚂蚁图团队GraphRAG支持社区摘要——Token相比微软直降50%全部内容,更多攻略请关注电脑114游戏。
电脑114游戏-好玩游戏攻略集合版权声明:以上内容作者已申请原创保护,未经允许不得转载,侵权必究!授权事宜、对本内容有异议或投诉,敬请联系网站管理员,我们将尽快回复您,谢谢合作!

