深度学习模型在信息排序中的应用
在之前的讨论中,我们已经探讨了信息检索的多样性、信息密度和质量等方面,主要集中在召回、融合和粗排的部分。而在本章中,我们将集中讨论信息排序的精排部分。粗排和精排的主要区别在于效率和效果的平衡。粗排模型的复杂度较低,需要在大幅度缩小召回候选量级的基础上和精排的排序一致性做尽可能的对齐,以保证精排高质量内容不被过滤。而精排模型的复杂度较高,可以使用更复杂的模型来尽可能地拟合最终的目标排序。在RAG任务中,最终目标是候选内容能够回答问题,客观评估即为推理引用率。
精排模型的训练目标通常有几种,包括全局优化的ListWise、每个item独立拟合ctr等直接目标的PointWise,以及对比优化的PairWise。在RAG的排序模块中,有多篇论文针对排序目标和样本的标注方式使用了以上不同方案进行了尝试。这些方案都可以直接使用大模型进行精排,也可以使用大模型来构建微调样本训练小模型。
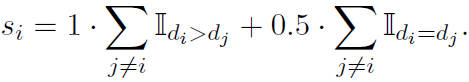
以上就是电脑114游戏给大家带来的关于深度学习模型在信息排序中的应用全部内容,更多攻略请关注电脑114游戏。
电脑114游戏-好玩游戏攻略集合版权声明:以上内容作者已申请原创保护,未经允许不得转载,侵权必究!授权事宜、对本内容有异议或投诉,敬请联系网站管理员,我们将尽快回复您,谢谢合作!

